
Il data mining cerca nei database gli schemi ricorrenti, o pattern, che non sono ancora stati trovati (discovery). Da questi schemi ricorrenti, da queste correlazioni, perfeziona modelli computazionali che descrivono le dinamiche dei processi in corso e ne predicono l’andamento futuro.
Descrizioni e predizioni basate su algoritmi di machine learning: per estrarre dai big data le informazioni più importanti rispetto agli obiettivi di business occorre servirsi dell’intelligenza artificiale.
Indice degli argomenti:
Cos’è il data mining
Il data mining è, letteralmente, “l’estrazione di dati”, ovvero il processo di selezione, esplorazione e analisi che permette di ricavare informazioni utili da grandi quantità di dati.
In particolare, il data mining trova le correlazioni e gli schemi ricorrenti (pattern) tra i dati che provengono da fonti spesso eterogenee, attraverso l’utilizzo di algoritmi di machine learning, ovvero di apprendimento automatico.

Video – Che cos’è il data mining – New Jersey Institute of Technology (in inglese)
Il data mining incrocia statistica, intelligenza artificiale, gestione del database: è una parte del processo di Knowledge Discovery in Database, che comprende la selezione, il pre-processing e la trasformazione dei dati, quindi il data mining, infine il riconoscimento dei pattern, la loro interpretazione e l’acquisizione di conoscenza.
Aspetti del pre-processing e della gestione del dato, oltre che dell’analisi vera e propria, sono quindi inclusi nel data mining.
In base alle problematiche del business e agli obiettivi da raggiungere, vengono scelti uno o più algoritmi di data mining appropriati: le informazioni ricavate, ad alto vantaggio competitivo, saranno impiegate come asset strategico delle operazioni aziendali.
Come funziona il data mining
Il data mining funziona attraverso algoritmi ottimizzati per individuare schemi ricorrenti o relazioni non note a priori tra grandi quantità di dati.
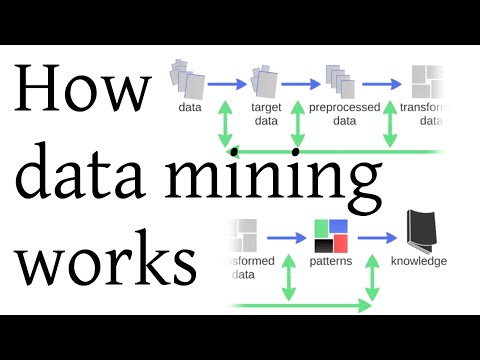
Video – Come funziona il data mining – Thales Sehn Körting (in inglese)
Un’attività di data mining può essere descrittiva, ovvero mirata a spiegare in modo più approfondito un determinato scenario, contemporaneo all’analisi; oppure può essere predittiva, ovvero mirata a elaborare un probabile scenario futuro sulla base dei dati a disposizione.
Sono descrittive le attività di clustering, association rule discovery, sequential pattern mining; sono predittive la classificazione e la regressione.
Il data mining si occupa di esplorare, riassumere, confrontare, generalizzare e verificare le caratteristiche dei dati: comprende dati quantitativi, qualitativi, testuali, immagini, suoni; permette di elaborare un numero cospicuo di variabili e non richiede ipotesi a priori.
Gli algoritmi di machine learning utilizzati per il data mining possono essere di apprendimento supervisionato o non supervisionato, a seconda che siano presenti o meno le “etichette” che contraddistinguono una classe di dati dall’altra.
Sono non supervisionati gli algoritmi di clustering, supervisionati quelli di classificazione.
Tecniche del data mining e esempi
Di seguito le principali tecniche di data mining:
Clustering
Il clustering, o cluster analysis, è una tecnica di data mining descrittiva, che consente di individuare gruppi di dati, o cluster, con caratteristiche simili. Nel clustering non ci sono etichette pre-definite: le nuove classi di dati, o sottoinsiemi, emergono dalla discovery del dataset. Gli algoritmi di clustering sono settati per massimizzare le similarità all’interno della stessa classe e minimizzare quelle tra classi.
Il clustering viene utilizzato per segmentare il database rispetto a target diversi e inviare comunicazioni di marketing mirato.
Regression
La regression, o analisi regressiva, è una tecnica predittiva. Viene usata per misurare i valori nel tempo di una variabile dipendente, sulla base della correlazione con una variabile indipendente.
Esistono diversi approcci all’analisi regressiva: la regressione lineare, la regressione lineare multipla, la regressione polinomiale, la regressione polinomiale multipla.
La regression si applica, ad esempio, per prevedere l’andamento dei prezzi, ma più in generale per l’analisi dei trend.
Association Rule Discovery
L’association rule discovery, o la scoperta delle regole associative, è una tecnica descrittiva che individua le regole di implicazione logica all’interno di un dataset, quindi i legami di correlazione e causalità che esistono tra dati diversi.
Si utilizza ad esempio nel marketing online per il cross-selling, la vendita di prodotti correlati all’interno di un e-commerce.
Sequential pattern mining
Il sequential pattern mining, o estrazione di pattern sequenziali, è una tecnica descrittiva con algoritmi di apprendimento supervisionato.
Un pattern sequenziale è una sottosequenza frequente: il compito dell’algoritmo è quello di trovare per quante volte si ripete nel database, anche in parte, nel minor tempo possibile.
Il sequential pattern mining viene utilizzato per individuare la storia degli acquisti generati da un cliente, o la storia degli eventi registrati da un sensore.
Classificazione
La classificazione è una tecnica predittiva, con algoritmi di apprendimento supervisionato. Date una o più classi, gli algoritmi trovano i dati a cui appartengono, descrivendoli e distinguendoli.
Tra le più diffuse tecniche di classificazione:
- Albero decisionale: è un grafo costruito in modo ricorsivo, con schema top-down. Alle radici si trova il dataset di training. I dati vengono ripartiti secondo gli input/attributi della classe, fino ad esaurimento degli attributi, o dei dati. È usato per individuare il miglior rapporto tra costi/benefici.
- Bayesian Belief Networks: è una tecnica che trova relazioni di influenza causale (del tipo if/then, “se…allora” tra subset di variabili.
- Backpropagation: si basa sulle reti neurali artificiali, che cambiano il peso dei diversi neuroni durante l’apprendimento. Reti feed-forward, a livelli, in cui il flusso di elaborazione procede in un’unica direzione, dal livello inferiore ai livelli superiori. Le modifiche ai pesi avvengono invece nella direzione opposta, “all’indietro”, dal livello superiore al livello inferiore: l’errore si “retropropaga” fin quando tutta la rete non sia aggiornata.
- Support Vector Machines: i “vettori di supporto” sono le tuple, ovvero le righe di database, di addestramento, che appartengono a due categorie. Dall’input iniziale, l’algoritmo deterministico trova una dimensione più ampia, un iperpiano di separazione lineare ottimale: in pratica, divide le due categorie iniziali con uno spazio più ampio possibile. E sulla base di questo, classifica i dati. Viene usato nel riconoscimento vocale o di immagini.
- Lazy learners: l’algoritmo “pigro” memorizza i dati di training e ritarda l’elaborazione fino alla consegna di una nuova tupla.
- Algoritmi genetici: dalla popolazione iniziale, con regole generiche e random, viene selezionata la più adatta a sopravvivere al contesto, finché la fitness della regola di classificazione individuata non è ottimale.
- Rough set approach: i set “rozzi” sono usati per definire classi equivalenti. Un set “rozzo” è formato da due sottoset: un’approssimazione più bassa e una più alta. L’obiettivo è trovare i sottoinsiemi minimi di attributi per la riduzione delle caratteristiche con una matrice di discernibilità.
- Fuzzy set approach: la logica fuzzy comprende infiniti valori tra zero e uno. Il fuzzy set approach rappresenta sia il grado di appartenenza di un dato a una categoria sia la categoria/Attributo in valori fuzzy, che sommati non arrivino a 1.
Data mining software
– IBM Intelligent Miner
– Oracle Data Mining
– Python
– RapidMiner
– SAS Enterprise Miner
– Xplenty
Open-source
– Apache Sparks
– Knime – Konstanz Information Miner
– Orange
– Rattle
– Weka
Differenza tra data mining e OLAP
Sia il data mining che l’OLAP – OnLine Analytical Processing sono soluzioni di business intelligence ma hanno caratteristiche diverse.
Mentre OLAP riassume i dati e fa previsioni di medio-lungo termine, il data mining scopre i pattern nascosti nei dati, scende in dettaglio anziché fare sintesi.
Inoltre, OLAP processa i dati online, il data mining non necessariamente. OLAP è guidato dalla query, il data mining dalla discovery.
Articolo originariamente pubblicato il 07 Mar 2022



