Imagen Video di Google e Make-a-Video di Meta sono i primi esempi delle capacità di alto livello dell’AI generativa. Il Generative Toolkit for Scientific Discovery (GT4SD) di IBM è una libreria open source che utilizza modelli generativi per generare nuovi progetti di molecole
I modelli di intelligenza artificiale generativa, in particolare quelli basati sul modello di diffusione, stanno guadagnando popolarità tra le aziende tecnologiche e i professionisti del machine learning per la loro capacità di creare immagini di alta qualità. Questo metodo sta sostituendo tecniche precedenti come le GAN e i trasformatori grazie ai suoi vantaggi in termini di qualità dell’immagine e affidabilità dell’addestramento.
Questi modelli funzionano aggiungendo rumore gaussiano ai dati di addestramento e poi imparando a recuperare i dati originali invertendo questo processo. Il risultato è una generazione di dati che mantiene la qualità e la struttura semantica dei dati di input. I modelli di diffusione non richiedono una formazione contraddittoria e sono stati utilizzati con successo per generare immagini, video, testo e dati sintetici.
I modelli di diffusione stanno trovando applicazioni in vari settori, dalla chimica alla progettazione di materiali, e stanno iniziando a essere utilizzati per la generazione di video e contenuti 3D. Tuttavia, la generazione iterativa richiede una notevole potenza di elaborazione, e la qualità delle immagini generate rimane una sfida.
I modelli di intelligenza artificiale generativa (AI) continuano a guadagnare popolarità e riconoscimento. I recenti progressi e il successo della tecnologia nel dominio della generazione di immagini hanno creato un’ondata di interesse tra le aziende tecnologiche e i professionisti dell’apprendimento automatico (ML), che ora stanno adottando costantemente modelli di intelligenza artificiale generativa per diversi casi d’uso aziendali. Un denominatore comune tra tutte le architetture generative di AI è l’uso di un metodo noto come modello di diffusione, che prende ispirazione dal processo fisico di diffusione delle molecole di gas, in cui le molecole diffondono da aree ad alta densità a quelle a bassa densità.
Indice degli argomenti:
Come funziona un modello di diffusione
Simile al processo scientifico, il modello inizia raccogliendo rumore casuale dai dati di input forniti, che viene sottratto in una serie di passaggi che creano un’immagine esteticamente piacevole e idealmente coerente. Guidando la rimozione del rumore in modo da favorire la conformità a un prompt di testo, i modelli di diffusione possono creare immagini con maggiore fedeltà.
Per l’implementazione dell’AI generativa, l’uso di modelli di diffusione è diventato evidente di recente, mostrando segni di prendere il posto di metodi passati come le reti antagoniste generative (GAN)e i trasformatori nel dominio della sintesi condizionale delle immagini, poiché i modelli di diffusione possono produrre immagini all’avanguardia mantenendo la qualità e la struttura semantica dei dati – e non essendo influenzati da inconvenienti di addestramento come il collasso della modalità.
Un nuovo modo di sintesi basato sull’intelligenza artificiale
Una delle recenti scoperte nella visione artificiale e nel ML è stata l’invenzione delle GAN, che sono modelli di intelligenza artificiale in due parti costituiti da un generatore che crea campioni e un discriminatore che tenta di distinguere tra i campioni generati e i campioni del mondo reale. Questo metodo è diventato un trampolino di lancio per un nuovo campo noto come modellazione generativa. Tuttavia, dopo aver attraversato una fase di boom, le GAN hanno iniziato a stabilizzarsi, poiché la maggior parte dei metodi ha faticato a risolvere i colli di bottiglia affrontati dalle tecniche contraddittorie, un metodo di apprendimento supervisionato dalla forza bruta in cui vengono forniti quanti più esempi possibili per addestrare il modello.
Le GAN funzionano bene per più applicazioni, ma sono difficili da addestrare e il loro output manca di diversità. Ad esempio, le GAN spesso soffrono di un addestramento instabile e di un collasso della modalità, un problema in cui il generatore può imparare a produrre solo un output che sembra più plausibile, mentre i modelli autoregressivi in genere soffrono di bassa velocità di sintesi.
Basandosi su tali arretrati, la tecnica del modello di diffusione ha avuto origine dalla stima probabilistica della verosimiglianza, un metodo per stimare l’output di un modello statistico attraverso osservazioni dai dati, trovando valori di parametri che massimizzano la probabilità di fare la previsione.
I modelli di diffusione sono modelli generativi (un tipo di modello di intelligenza artificiale che impara a modellare la distribuzione dei dati dall’input). Una volta appresi, questi modelli possono generare nuovi campioni di dati simili a quelli su cui vengono addestrati. Questa natura generativa ha portato alla sua rapida adozione per diversi casi d’uso come la generazione di immagini e video, la generazione di testo e la generazione di dati sintetici per citarne alcuni.
I modelli di diffusione funzionano decostruendo i dati di addestramento attraverso l’aggiunta successiva di rumore gaussiano e quindi imparando a recuperare i dati invertendo questo processo di noising. Dopo l’addestramento, il modello può generare dati semplicemente passando il rumore campionato casualmente attraverso il processo di de-noising appreso. Questa procedura di sintesi può essere interpretata come un algoritmo di ottimizzazione che segue il gradiente della densità dei dati per produrre campioni probabili.
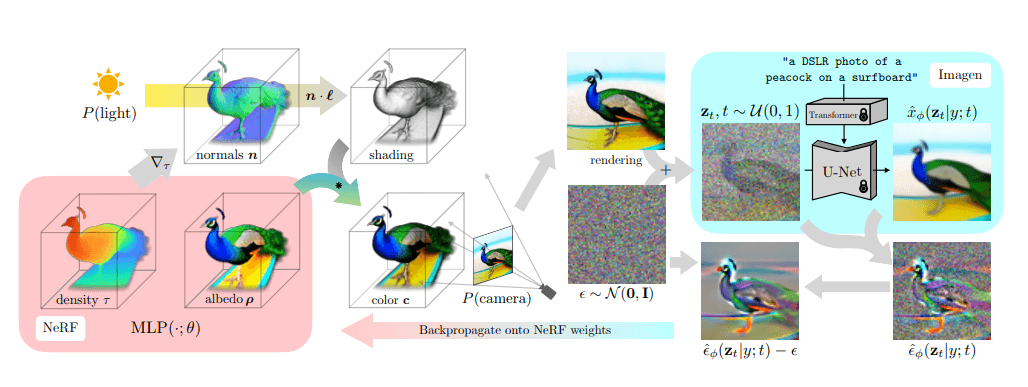
La diffusione e la ricostruzione 3D dall’architettura del processo testuale
Fonte immagine: DreamFusion
Oltre a una maggiore qualità dell’immagine, i modelli di diffusione hanno molti altri vantaggi e non richiedono una formazione contraddittoria. Altri metodi ben noti, come i trasformatori, richiedono enormi quantità di dati e affrontano un plateau in termini di prestazioni nei domini di visione rispetto ai modelli di diffusione.
Attuale adozione da parte del mercato di modelli di diffusione
L’utilizzo di modelli di diffusione per l’intelligenza artificiale generativa può aiutare a sfruttare diverse funzionalità uniche, tra cui la creazione di immagini diverse e il rendering del testo in diversi stili artistici, la comprensione 3D e l’animazione.
Progredendo dalla semplice sintesi delle immagini, le capacità di questi modelli di nuova generazione si stanno spostando verso la generazione di video e 3D. Imagen Video di Google e Make-a-Video di Meta sono i primi esempi delle capacità di alto livello dell’AI generativa.
Imagen Video è costituito da un codificatore di testo (congelato T5-XXL), un modello di diffusione video di base e modelli di diffusione spaziale e temporale a super-risoluzione interlacciati. Allo stesso modo, i modelli di diffusione video (VDM) di Make-a-Video utilizzano una U-Net fattorizzata spazio-temporale con dati di immagini e video congiunti. formazione. Inoltre, VDM è stato addestrato su 10 milioni di coppie di set di dati open source testo-video privati, il che ha reso più facile per il modello produrre video dal testo fornito.
Il team di ricerca AI di IBM ha recentemente integrato i modelli di diffusione come una delle sue tecniche, utilizzandoli per applicazioni come la chimica, la progettazione e la scoperta di materiali. Il Generative Toolkit for Scientific Discovery (GT4SD) di IBM è una libreria open source che utilizza modelli generativi per generare nuovi progetti di molecole basati su proprietà come proteine bersaglio, profili omici bersaglio (cioè genomica, trascrittomica, proteomica o metabolomica), distanze di impalcature, energie di legame e target aggiuntivi rilevanti per la scoperta di materiali e farmaci.
GT4SD include una vasta gamma di modelli generativi e metodi di addestramento, tra cui autoencoder variazionali, modelli da sequenza a sequenza e modelli di diffusione, in cui l’obiettivo è fornire e collegare modelli e metodi generativi all’avanguardia per diverse sfide di scoperta scientifica.
Opportunità e sfide future per i modelli di diffusione
Secondo William Falcon, cofondatore e CEO di Lightning AI, i modelli di diffusione svolgeranno un ruolo essenziale nell’evoluzione generativa dell’AI in quanto non presentano svantaggi apprezzabili rispetto alle architetture precedenti, con l’unica eccezione che la loro generazione è iterativa e richiede potenza di elaborazione aggiuntiva.
“Un’area [dove] mi aspetto di vedere la diffusione giocare un ruolo importante è nella costruzione di giochi e prodotti VR e AR”, ha affermato. “Stiamo già iniziando a vedere la comunità sperimentare ambienti immersivi basati sulla diffusione e la generazione di risorse da singoli scatti. La generazione di asset è sempre stata un grande ostacolo nel far prosperare i mondi virtuali e la diffusione ha il potere di cambiare tutto anche lì”.
Falcon afferma che, sebbene i modelli di diffusione liberino una dimensione completamente nuova di creatività per le persone per esprimersi, la sicurezza è e continuerà a essere un grande tema.
Allo stesso modo, Fernando Lucini, Global Lead for Data Science & Machine Learning Engineering di Accenture, ha affermato che la qualità delle immagini generate rimane una sfida per il prossimo futuro. Lucini ritiene che il futuro di questi modelli sia nella generazione di immagini e video da testo semplice, che possono svolgere un ruolo nell’evoluzione di macchine generative sostanziali con cui possiamo interagire più frequentemente.
Su questo sito utilizziamo cookie tecnici necessari alla navigazione e funzionali all’erogazione del servizio.
Utilizziamo i cookie anche per fornirti un’esperienza di navigazione sempre migliore, per facilitare le interazioni con le nostre funzionalità social e per consentirti di ricevere comunicazioni di marketing aderenti alle tue abitudini di navigazione e ai tuoi interessi.
Puoi esprimere il tuo consenso cliccando su ACCETTA TUTTI I COOKIE. Chiudendo questa informativa, continui senza accettare.
Potrai sempre gestire le tue preferenze accedendo al nostro COOKIE CENTER e ottenere maggiori informazioni sui cookie utilizzati, visitando la nostra COOKIE POLICY.
ACCETTA
PIÙ OPZIONI
Cookie Center
ACCETTA TUTTO
RIFIUTA TUTTO
Tramite il nostro Cookie Center, l'utente ha la possibilità di selezionare/deselezionare le singole categorie di cookie che sono utilizzate sui siti web.
Per ottenere maggiori informazioni sui cookie utilizzati, è comunque possibile visitare la nostra COOKIE POLICY.
ACCETTA TUTTO
RIFIUTA TUTTO
COOKIE TECNICI
Strettamente necessari
I cookie tecnici sono necessari al funzionamento del sito web perché abilitano funzioni per facilitare la navigazione dell’utente, che per esempio potrà accedere al proprio profilo senza dover eseguire ogni volta il login oppure potrà selezionare la lingua con cui desidera navigare il sito senza doverla impostare ogni volta.
COOKIE ANALITICI
I cookie analitici, che possono essere di prima o di terza parte, sono installati per collezionare informazioni sull’uso del sito web. In particolare, sono utili per analizzare statisticamente gli accessi o le visite al sito stesso e per consentire al titolare di migliorarne la struttura, le logiche di navigazione e i contenuti.
COOKIE DI PROFILAZIONE E SOCIAL PLUGIN
I cookie di profilazione e i social plugin, che possono essere di prima o di terza parte, servono a tracciare la navigazione dell’utente, analizzare il suo comportamento ai fini marketing e creare profili in merito ai suoi gusti, abitudini, scelte, etc. In questo modo è possibile ad esempio trasmettere messaggi pubblicitari mirati in relazione agli interessi dell’utente ed in linea con le preferenze da questi manifestate nella navigazione online.