
Due gruppi di ricerca californiani hanno sviluppato impianti cerebrali che, a loro dire, sarebbero molto più efficaci dei dispositivi precedenti nel dare voce alle persone che non possono parlare.
I due gruppi, che lavorano indipendentemente presso l’Università della California di San Francisco e l’Università di Stanford, hanno utilizzato nuovi array di elettrodi e programmi di intelligenza artificiale per trasformare i pensieri in testi e parole. Gli scienziati della UCSF hanno anche progettato un avatar realistico per pronunciare le parole decodificate.
I dettagli di entrambe le interfacce cervello-computer sono stati pubblicati congiuntamente sulla rivista Nature il 23 agosto.
Indice degli argomenti:
Come sono fatti gli impianti cerebrali
“Entrambi gli studi rappresentano un grande balzo in avanti verso la decodifica dell’attività cerebrale con la velocità e la precisione necessarie per ripristinare una comunicazione fluente nelle persone con paralisi [vocale]”, dichiara Frank Willett, uno dei membri del team di Stanford.
I due impianti sono significativamente diversi nel design.
Il team dell’UCSF ha posizionato un rettangolo sottile come carta con 253 elettrodi sulla superficie della corteccia per registrare l’attività cerebrale di un’area notoriamente critica per il linguaggio.
Il dispositivo di Stanford ha inserito due matrici più piccole con un totale di 128 micro-elettrodi più in profondità nel cervello.
Ogni team ha lavorato con un singolo volontario: Stanford con Pat Bennett, 68 anni, affetto da sclerosi laterale amiotrofica, e UCSF con una paziente di 47 anni colpita da ictus, nota come Ann. I segnali provenienti dal cervello di Ann vengono convertiti in linguaggio decodificato tramite un avatar.
Video: test su un paziente del sistema ideato dai ricercatori dell’Università della California di San Francisco e l’Università di Stanford (fonte Nature)
I risultati della ricerca
Nonostante le differenze tra gli impianti e i partecipanti alla ricerca, i risultati dei due studi sono stati sostanzialmente simili. Hanno raggiunto una velocità media di circa 60-80 parole al minuto, quasi la metà della velocità di una normale conversazione, ma almeno tre volte più veloce di qualsiasi altra precedente interfaccia cervello-computer.
Entrambi i progetti hanno utilizzato un algoritmo di intelligenza artificiale per decodificare i segnali elettrici provenienti dal cervello del soggetto, insegnandogli a distinguere il modello distinto associato ai singoli fonemi, le sotto-unità del discorso che formano le parole. I sistemi necessitavano di lunghe sessioni di addestramento – 25 nel caso di Bennett, ciascuna della durata di quattro ore – durante le quali ripeteva nella sua mente diverse frasi scelte da un ampio set di dati di conversazioni telefoniche.
“Questi risultati iniziali hanno dimostrato il concetto, e alla fine la tecnologia lo raggiungerà per renderlo facilmente accessibile alle persone che non possono parlare”, ha scritto Bennett. “Per coloro che non sono in grado di parlare, questo significa che possono rimanere collegati al mondo esterno, magari continuare a lavorare, mantenere amici e relazioni familiari”.
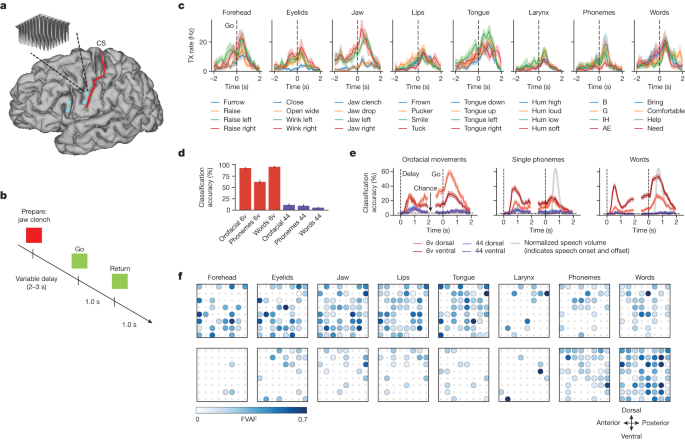
Rappresentazione neurale del movimento orofacciale e del tentativo di parlare (fonte Nature)
Un software che simula i movimenti del viso
Gli scienziati della UCSF, in collaborazione con i colleghi della UC Berkeley, hanno creato una voce personalizzata per Ann, basandosi su una registrazione del suo discorso al matrimonio. Hanno anche creato un avatar per lei, utilizzando un software che simula i movimenti dei muscoli del viso di Speech Graphics, un’azienda di Edimburgo che produce software di animazione facciale.
I segnali provenienti dal cervello di Ann mentre cercava di parlare sono stati convertiti in movimenti corrispondenti sul volto dell’avatar. “Quando il soggetto ha usato per la prima volta questo sistema per parlare e muovere il volto dell’avatar in tandem, ho capito che si sarebbe trattato di qualcosa che avrebbe avuto un impatto reale”, afferma Kaylo Littlejohn della UC Berkeley.
Video: un altro test eseguito sul paziente, che in questo caso resta in silenzio mentre “pensa” le frasi che legge sul display
Sarà necessario un ulteriore lavoro di sviluppo per tradurre la prova di laboratorio in dispositivi abbastanza semplici e sicuri da poter essere utilizzati a casa dai pazienti e da chi li assiste. Un passo importante, dicono i ricercatori, sarà quello di produrre una versione wireless che non richieda all’utente di essere collegato all’impianto.
In un editoriale di Nature, due neurologi non coinvolti nella ricerca, Nick Ramsey dell’Università di Utrecht e Nathan Crone della Johns Hopkins University, hanno definito i risultati “un grande progresso nella ricerca neuroscientifica e neuroingegneristica, [che] mostra grandi promesse nell’alleviare le sofferenze degli individui che hanno perso la voce a causa di lesioni e malattie neurologiche paralizzanti”.
Nota:
Questo articolo è rilasciato sotto una licenza Creative Commons Attribuzione 4.0 Internazionale, che consente l’uso, la condivisione, l’adattamento, la distribuzione e la riproduzione in qualsiasi mezzo o formato, purché si dia il giusto credito all’autore originale (i) e alla fonte, fornire un link alla licenza Creative Commons e indicare se sono state apportate modifiche. Le immagini o altro materiale di terze parti in questo articolo sono inclusi nella licenza Creative Commons dell’articolo, se non diversamente indicato in una linea di credito al materiale.
Per visualizzare una copia di questa licenza, visitare il sito Web
Creative Commons — Attribution 4.0 International — CC BY 4.0



