
Technology Vision 2023 è un recente report rilasciato da Accenture che esplora le tendenze tecnologiche che guidano la nuova realtà e i passi che le aziende dovranno compiere per prosperare. All’interno del report, Generalizing AI esplora il modo in cui una nuova categoria di AI, stimolata dai foundation model e dai modelli linguistici di grandi dimensioni (LLM), sta diventando un punto di riferimento per tutte le aziende che operano nel mercato.
Indice degli argomenti:
Technology Vision 2023 di Accenture: tutto ha origine dai dati
Con l’enorme volume di dati e approfondimenti necessari per trovare soluzioni ai problemi che le imprese devono affrontare, i leader aziendali dovranno fare affidamento su tutte le capacità offerte dall’AI generativa e dalla prossima generazione di AI.
Technology Vision traccia il percorso che inizia con la fusione tra fisico e digitale, prosegue con i problemi insolubili che le aziende stanno iniziando a risolvere e si conclude con la rivoluzione della tecnologia scientifica che sta portando vere novità alle aziende e al mondo.
In Identità digitale si discute di come l’identità sia il silenzioso catalizzatore di questa prossima generazione di innovazione. Le nostre più grandi ambizioni tecnologiche sono frenate da vecchi modelli di identità. La convergenza fisico-digitale si innescherà solo quando persone e cose avranno un’identità in grado di attraversare entrambe le parti. Le forme emergenti di identità digitale stanno finalmente abbattendo i muri che dividono le imprese e le vite fisiche e digitali delle persone, dando il via a un torrente di cambiamenti.
I tuoi dati, i miei dati, i nostri dati esplora come la trasparenza sarà una risorsa preziosa per le aziende che vogliono guidare questi cambiamenti. L’offerta e la domanda di dati da parte di tutti gli stakeholder aziendali è in forte aumento. Le aziende dovranno ripensare la raccolta dei dati e la progettazione dell’architettura per iniziare a esporre i dati che contano. I leader hanno un’opportunità senza precedenti di costruire la fiducia con partner e clienti diventando proattivamente più trasparenti, oppure rischiano che qualcun altro lo faccia per loro. Ma il compito di costruire questa nuova realtà non sarà solo per gli esseri umani.
Accenture ha condotto l’indagine Technology Vision 2023 su 4.777 dirigenti e direttori di livello C in 25 settori per capire le loro prospettive e l’uso delle tecnologie emergenti nelle loro organizzazioni. I sondaggi sono stati condotti da dicembre 2022 a gennaio 2023 in 34 Paesi.
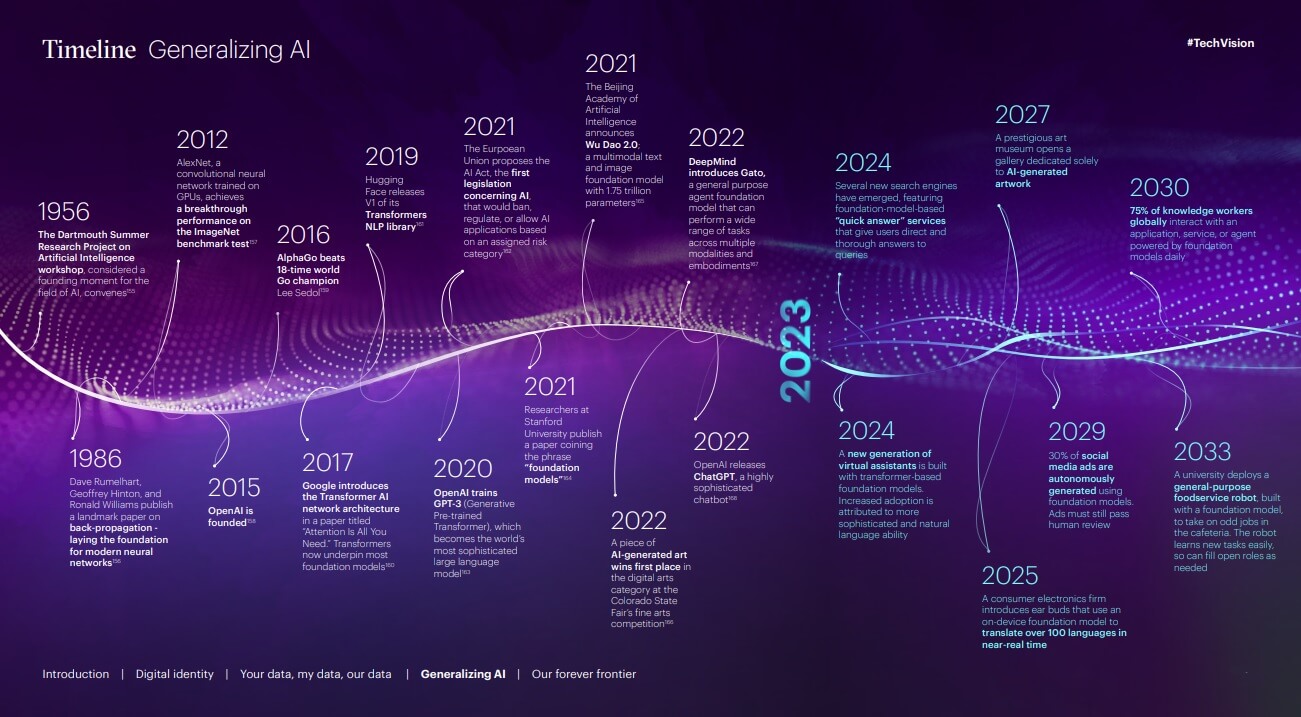
Il quadro generale dell’AI generativa
Quando OpenAI ha rivelato ChatGPT alla fine del 2022, le persone si sono precipitate a testarlo. E prima di ChatGPT, Internet era invasa da arte generata dall’intelligenza artificiale. Generatori di testo-immagine come Stability AI’s Stable Diffusion e OpenAI’s DALL-E 2 hanno stupito le persone rispondendo a richieste scritte con immagini fotorealistiche.
Questo contenuto generato fa parte di uno dei più grandi cambiamenti nella storia dell’AI: l’introduzione di modelli preaddestrati con una notevole adattabilità ai compiti.
Tutto è iniziato con un’innovazione storica nell’architettura dei modelli di AI da parte dei ricercatori di Google nel 2017. Da allora, le aziende tecnologiche e i ricercatori hanno aumentato le dimensioni dell’AI aumentando le dimensioni dei modelli e dei set di addestramento. Il risultato? Potenti modelli preaddestrati, spesso chiamati “modelli di base” o foundation model, che offrono un’adattabilità senza precedenti all’interno dei domini su cui vengono addestrati.
Con i modelli di base, le aziende possono iniziare ad affrontare molte attività e sfide in modo diverso, spostando l’attenzione dalla costruzione della propria AI all’apprendimento della costruzione con l’AI.
Una base per le scoperte dell’intelligence
GPT-3 di OpenAI, rilasciato nel 2020, era il modello linguistico più grande al mondo. Ha imparato da solo a svolgere compiti per i quali non era mai stato addestrato e ha superato i modelli che erano stati addestrati per tali compiti. Da allora, aziende come Google, Microsoft e Meta hanno creato i propri modelli linguistici di grandi dimensioni.
Per definire questa nuova classe di AI, i ricercatori dello Stanford Institute for Human-Centered Artificial Intelligence hanno coniato il termine “foundation model”. In generale, li definiscono come modelli di AI di grandi dimensioni addestrati su una vasta quantità di dati con una significativa adattabilità ai compiti a valle.
Alcuni stanno lavorando per espandere i modelli di fondazione al di là del linguaggio e delle immagini per includere altre modalità di dati. Meta, ad esempio, ha sviluppato un modello che apprende il “linguaggio delle proteine” e accelera le previsioni della struttura proteica fino a sessanta volte.
Sono in corso molti sforzi per semplificare la costruzione e l’implementazione dei modelli di fondazione. I requisiti di calcolo in rapida crescita – e i costi associati e le competenze necessarie per gestire questa scala – sono oggi i maggiori ostacoli. E anche dopo che un modello è stato addestrato, è costoso eseguire e ospitare le sue variazioni a valle.
Una trasformazione del lavoro e della vita guidata dall’intelligenza artificiale
La domanda per le aziende non è se questi modelli avranno un impatto sul loro settore, ma come.
I modelli di fondazione hanno il potenziale per trasformare l’interazione uomo-AI. Alcuni definiscono ChatGPT il futuro della ricerca e del recupero della conoscenza. È in grado di scrivere poesie e saggi, di eseguire il debug del codice e di rispondere a domande complicate perché è stato addestrato su miliardi di esempi online. Inoltre, ricorda le conversazioni precedenti, in modo da poter rivedere o elaborare le risposte, rendendo la comunicazione uomo-macchina più sofisticata e naturale.
I foundation model
I foundation model stanno anche aprendo le porte a nuove applicazioni e servizi di AI che prima erano difficili o impossibili da realizzare. La mancanza di dati di addestramento è un problema importante per la maggior parte delle organizzazioni. Ma i modelli di base preaddestrati possono aiutare ad aggirare questa limitazione.
Anche i foundation model multimodali stanno facendo passi da gigante. Cosa saremo in grado di fare quando i modelli multimodali collegheranno testo, suono, immagini, video, dati spaziali 3D, dati dei sensori, dati ambientali e altro ancora? Un’apparecchiatura industriale, ad esempio, potrebbe utilizzare un sistema di intelligenza artificiale per tradurre i dati di decine di sensori in una procedura di riparazione per un meccanico.
Le organizzazioni che hanno costruito modelli di base preaddestrati li rendono disponibili attraverso canali open-source o con accesso a pagamento tramite API.
Per costruire una strategia intorno ai foundation model è necessario innanzitutto comprendere i loro migliori casi d’uso. Alcune applicazioni di AI lavorano con tipi di dati che nessun modello di base è ancora in grado di gestire. Altre ancora sono meglio servite da un’intelligenza artificiale ristretta, addestrata per un compito specifico. Inoltre, la parzialità dei modelli di base è un problema comune a causa dell’omogeneizzazione e del fatto che molti di essi vengono addestrati su grandi set di dati online.
Conclusioni
Secondo il Technology Vision 2023 di Accenture, anche se il linguaggio naturale offre un’interfaccia facile da usare, sono necessarie alcune conoscenze di ingegneria del software per costruire applicazioni di successo attorno ai modelli di fondazione. Le aziende che non hanno queste competenze possono comunque trarre vantaggio dalla tecnologia. Sulla scia di OpenAI e di altri che hanno trasformato i loro modelli in piattaforme, un’ondata di aziende ha iniziato a offrire nuovi prodotti e servizi B2B.
Alla fine, le operazioni di AI si sposteranno dalla creazione di modelli alla costruzione di modelli. I talenti in grado di prendere i modelli di base, adattarli alle esigenze aziendali e integrarli nelle applicazioni diventeranno sempre più importanti.


