
- I modelli Transformer sono emersi come una tecnologia rivoluzionaria nel campo del machine learning e dell’intelligenza artificiale, superando i limiti delle reti neurali ricorrenti (RNN) nella comprensione del linguaggio naturale. Questi modelli hanno permesso la creazione di strumenti avanzati come BERT e ChatGPT, che hanno migliorato significativamente le prestazioni nel Natural Language Processing (NLP).
- I Transformer utilizzano un meccanismo di “self-attention” che permette di focalizzarsi su elementi specifici della sequenza di input, migliorando la comprensione del testo. A differenza delle RNN, che elaborano gli input in modo sequenziale, i Transformer possono gestire sequenze di lunghezza arbitraria in parallelo, rendendoli più efficienti e scalabili. La loro architettura include componenti innovativi come il “positional encoding” e i blocchi di “multi-head attention”.
- I Transformer hanno dimostrato una superiorità rispetto alle RNN in molte applicazioni NLP, ma presentano anche sfide in termini di complessità computazionale. La crescita della complessità è quadratica rispetto alla lunghezza delle sequenze di input, rendendo l’addestramento costoso. Varianti come Longformer e Linear Transformer sono state sviluppate per mitigare questi problemi, migliorando l’efficienza e permettendo l’elaborazione di sequenze più lunghe.
Una delle tecnologie più promettenti nell’ambito del Machine learning e dell’intelligenza artificiale, una nuova architettura, introdotta nel 2017 per migliorare le prestazioni e superare i limiti delle reti neurali ricorrenti nella comprensione del linguaggio naturale, ha avuto un successo e una diffusione eccezionali favorendo la costruzione di modelli come BERT, ChatGPT e i loro simili meno pubblicizzati ma non meno potenti; sono i modelli Transformer.
Indice degli argomenti:
Cosa sono le Reti Neurali Transformer
Facciamo un passo indietro e torniamo alle RNN, le reti neurali ricorrenti (Reti neurali ricorrenti (RNN), cosa sono, come funzionano – AI4Business); queste sono particolarmente efficaci nella gestione di sequenze di dati. Una tipologia di RNN è quella nota come seq2seq (sequence to sequence o many-to-many) e trasforma una sequenza di elementi come delle parole, in un’altra sequenza di elementi. Per questo hanno prestazioni eccezionali per compiti di traduzione automatica, una sequenza di parole in una lingua viene trasformata in una sequenza di parole in un’altra lingua. Tra le seq2seq è molto efficace il modello LSTM (long-Short-Term-Memory) che memorizza le dipendenze tra termini importanti in sequenze molto lunghe. Tuttavia, questi modelli di reti neurali sono sempre più difficili da gestire all’aumentare della lunghezza delle sequenze.
L’idea geniale per superare i limiti delle RNN è stata quella di abbandonare la ricorrenza e introdurre un meccanismo che permette di focalizzare l’attenzione su particolari elementi della sequenza e di stabilire i riferimenti tra essi. Proprio come durante l’ascolto o la lettura di una frase il cervello umano si focalizza su alcune parole di maggiore importanza e stabilisce i riferimenti tra pronomi, sostantivi e altre entità, una rete neurale costruita sulla base di un modello transformer è in grado di individuare le parole importanti della sequenza di input e stabilire i loro riferimenti con una migliore comprensione del testo.
I transformer sono in grado di elaborare gli input in modo parallelo e con sequenze arbitrariamente lunghe, mentre le RNN procedono in modo sequenziale e con un limite sulla lunghezza delle sequenze in input; queste differenze rendono i transformer più vantaggiosi dei modelli di reti neurali precedenti soprattutto nel contesto del NLP (Natural Language Processing). Inoltre, i Transformer permettono un design relativamente semplice che favorisce l’applicazione a molteplici tipi di dato oltre al testo, come video e immagini, con architettura e blocchi di elaborazione simili e con un’eccellente scalabilità rispetto a grandi moli di dati. Lo sviluppo dei Transformer si può dire che è stato l’inizio dei Large Language Model, modelli addestrati con una quantità gigantesca e sempre crescente di dati e di parametri per operare nel contesto del NLP e in altri contesti dell’intelligenza artificiale.
Come funzionano le Reti Neurali Transformer?
Prima di una descrizione sintetica dello schema facciamo qualche esempio su dei testi per capire come vengono affrontate la “comprensione” e la “traduzione”.
Una semplice affermazione in inglese “the red hat” in italiano “il cappello rosso”, è un evidente esempio che in lingue diverse l’ordine e la posizione di aggettivi, verbi o altre parti del discorso, non è la stessa. Consideriamo due frasi simili prese da un link di approfondimento citato a fine paragrafo:
“l’animale non attraversò la strada perché era troppo stanca”
“l’animale non attraversò la strada perché era troppo larga”
Non è semplice (per un sistema software) stabilire che nella prima frase “troppo stanca” si riferisce all’animale, mentre nella seconda frase, “troppo larga” si riferisce alla strada.
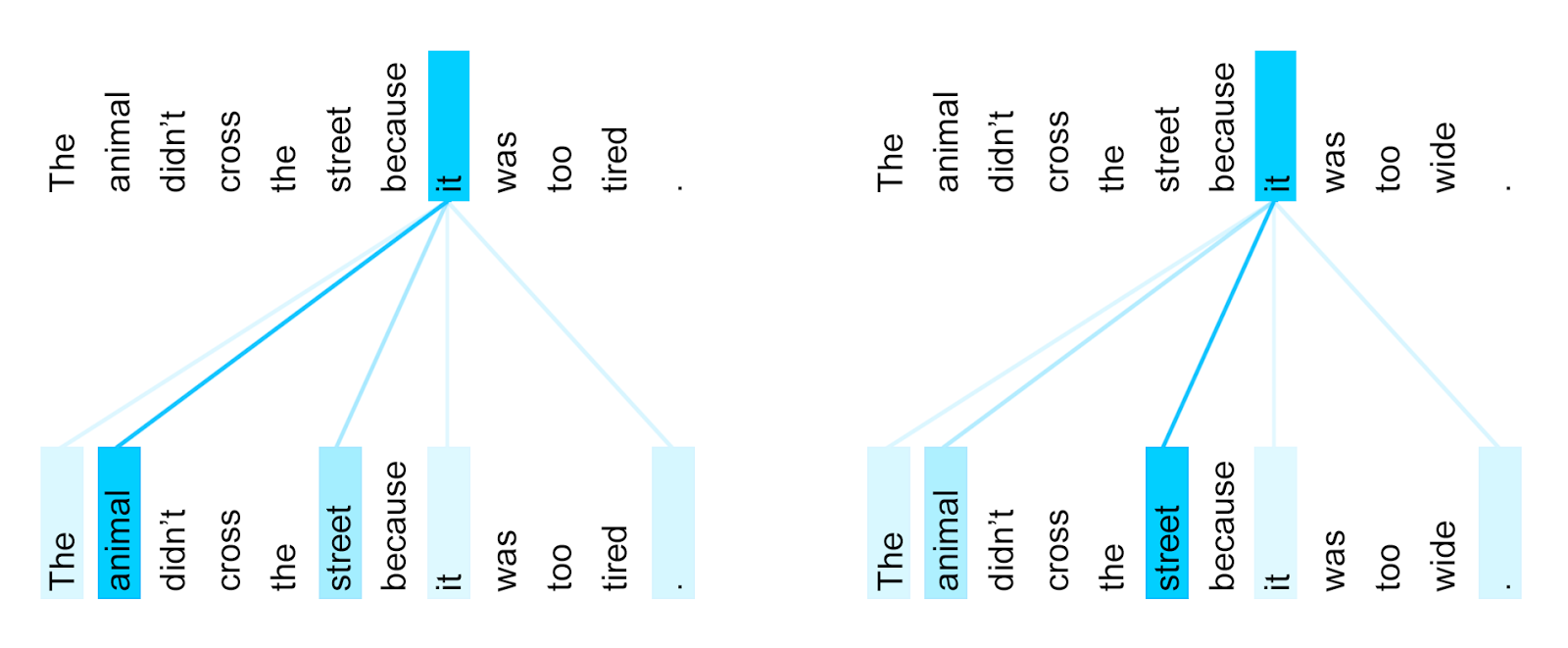
I due esempi sono un assaggio delle difficoltà di un sistema automatico nel comprendere un testo che per un essere umano è quasi banale. Il meccanismo di self-attention introdotto nel 2017 semplifica questa attività che in casi di altri modelli di reti neurali è molto più complessa da realizzare. Un modello equipaggiato con le funzionalità di un Transformer è in grado di dare il peso corretto alle parole nelle due frasi ed è in grado di distinguere a chi sono riferite le parole “troppo larga” o “troppo stanca” nella frase.
Un tipico modello transformer è quello rappresentato nella seguente figura, che in quasi ogni pubblicazione o libro viene riportata; è esattamente la stessa dell’articolo del 2017 che segna la creazione dei Transformer (Vaswani e altri).
Può sembrare complesso, ma è una architettura come quella di altre reti neurali, con l’aggiunta di due nuovi elementi, il “positional encoding” e i blocchi di “attention” che sono la vera innovazione.

Per semplicità facciamo sempre riferimento all’analisi di un testo e alla sua traduzione. Il blocco di sinistra è un encoder, analizza il testo in input e lo traduce in qualcosa di internamente elaborabile nei livelli della rete neurale. Il blocco sulla destra è un decoder e traduce quello che è stato codificato dall’encoder internamente, nel testo di output.
Il blocco “positional encoding” si occupa di quello che nei modelli precedenti era gestito con un’architettura ricorrente; poiché non si usa più una RNN, è necessario un altro tipo di modulo che dia ad ogni parola della sequenza il suo giusto posto corrispondente alla lingua in cui è scritto il testo.
Una volta che il “positional encoding” garantisce l’ordine corretto dei termini nella sequenza di input, interviene il meccanismo di “attention”; questo, nella sua forma più semplice “self-attention” per ogni parola nella frase calcola un punteggio di importanza rispetto ad ogni altra parola.
Riprendiamo l’esempio della traduzione “il cappello rosso” in inglese; il meccanismo di self-attention, per esempio calcola il punteggio della parola “rosso” rispetto alle altre; tale punteggio determina (nella frase di output in inglese) un peso di quanto ogni altra parola dovrà contribuire alla parola “rosso” (in questo caso “red”) nell’output corrispondente.
Il meccanismo risulta molto dispendioso a livello computazionale, inoltre i modelli sono molto complessi e un solo self-attention non è sufficiente, ma il trucco è quello di usare molti meccanismi di attention in parallelo creando i blocchi “Multi-Head-Attention”.
Il calcolo nei blocchi “multi-head” può essere fatto in parallelo perché non ci sono dipendenze tra i vari blocchi.
L’addestramento di un modello transformer richiede un numero enorme di input anche a causa del non utilizzo di strutture ricorrenti, ma la possibilità di utilizzare blocchi che possono essere elaborati in parallelo, ne fa ancora un modello vantaggioso rispetto ai precedenti.
Per approfondire gli argomenti a livello tecnico si possono consultare le pubblicazioni online dei ricercatori su Google Research e i tutorial sull’implementazione e l’uso dei modelli con Tensorflow e con PyTorch.

Chi ha creato i Transformer?
Nel 2017 Ashish Vaswani e altri ricercatori di Google Brain, la divisione di ricerca dedicata all’intelligenza artificiale, in un articolo dal titolo “Attention is all you need , rendono noti i risultati delle loro ricerche e introducono il concetto alla base dei modelli transformer: il “self-attention mechanism”. Con questa pubblicazione è iniziata la rivoluzione nel campo dell’elaborazione del linguaggio naturale che attualmente suscita opinioni contrapposte e paure sui tremi dell’intelligenza artificiale. Il gruppo degli otto ricercatori ha introdotto i concetti di “self-attention”, “multi-head attention”, “Transformer” e ha proposto un modello che non utilizzasse le reti neurali ricorrenti e le convoluzionali. I risultati ottenuti da esperimenti di traduzione inglese-tedesco e inglese-francese hanno evidenziato la qualità superiore e il minor tempo di addestramento del nuovo modello.
L’evoluzione di questi nuovi modelli è stata esponenziale, i Transformer hanno dimostrato la superiorità sulle architetture basate su RNN in molte aree del Natural Language Processing, in particolare nella traduzione automatica, nella comprensione e generazione di testo, ma anche in altri contesti come analisi e generazione di immagini, sistemi decisionali più efficienti in ambito medicale, supporto all’ analisi dei dati forniti dai telescopi in astronomia.
Nella proposta iniziale furono introdotti i meccanismi di “attention” e “multi-head attention” in una prima versione che si è evoluta nei modelli sviluppati negli anni successivi da aziende quali Google, OpenAI, Deep Mind e altre.
Ma anche i transformer non sono esenti da difficoltà come vedremo nel prossimo paragrafo.

A sinistra, attenzione al prodotto punto in scala. A destra, Multi-Head Attention è costituito da diversi livelli di attenzione che corrono in parallelo
Risolvere il problema della complessità nelle reti Transformer
Una rete basata sul modello transformer, sebbene di livello superiore rispetto alle precedenti RNN e LSTM, ha una complessità che cresce in modo quadratico con la lunghezza delle sequenze di input; questo significa che raddoppiando la lunghezza del testo in input, la complessità di calcolo crescerà di 4 volte, triplicando la lunghezza crescerà di 9 volte e così via. In sostanza l’addestramento di modelli che possono ricevere in input testi molto lunghi è molto costoso a livello computazionale e richiede sia più tempo sia un maggior numero di parametri.
Oltre alla creazione di nuovi modelli basati su reti transformer, la ricerca si concentra sulla risoluzione di questo problema, attualmente proponendo alcune varianti.
Una prima variante è, data una sequenza di input, considerare nel meccanismo di attention solo gli ultimi N elementi invece che tutta la sequenza, riducendo così il numero di operazioni eseguite. Questo corrisponde a ridurre il contesto di intervento della self-attention; il modello prende il nome di Longformer e opera su una finestra di N elementi; la finestra scorre con l’elaborazione degli input così da considerare solo gli ultimi N. Alcune varianti di Longformer sono sparse-attention, hierarchical transformer, recurrent transformer che recuperano concetti di altri modelli di reti neurali.
Una seconda tipologia di intervento viene attuata con una diversa modalità di calcolo dell’attention; si interviene a livello di algebra, riducendo il numero di operazioni e trasformando il problema in lineare; il modello si chiama Linear Transformer.
Entrambi gli approcci permettono di estendere la lunghezza massima della sequenza di input, che nel caso di NLP è la lunghezza massima del testo in input alla rete neurale. Oltre all’estensione della lunghezza dei dati di input entrambe le varianti risultano più vantaggiose in termini di calcolo.
I modelli NLP basati su BERT
Dal lavoro fatto nel 2017 nel gruppo di ricerca Google sui Transformer, sia la stessa Google sia altre entità hanno investito in ricerche e sviluppi su questi nuovi modelli. I primi risultati si sono visti con BERT (Bidirectional Encoder Representation from Transformers) introdotto da Google nel 2018. La caratteristica innovativa di BERT è nella prima parola, “bidirectional”. BERT implementa dei multi-head-attention bidirezionali, ovvero oltre che nel senso di lettura di un testo anche a ritroso; inoltre, riesce a predire parole mancanti (mascherate) in una frase.
BERT è ancora oggi un modello molto complesso che può essere utilizzato in forma open-source per automatizzare processi di NLP e può essere adattato al proprio contesto applicativo con un processo di “fine-tuning”. Contestualmente altri modelli concorrenti sono stati sviluppati e diffusi, tra cui GPT e i suoi successori, altri modelli derivati di BERT; tra questi ultimi citiamo BART (Bidirectional and Auto Regressive Transformers) e, annunciato a febbraio 2023, BARD. Sembra che non ci sia un acronimo per BARD, ma che la “D” stia per “Dialog applications”.
BARD è costruito su una tecnologia che Google sta sperimentando, LaMDA (Language Model for Dialog Applications) e che molto cautamente sta rilasciando per competere con i modelli sviluppati e diffusi da OpenAI. A questo proposito si può leggere un confronto fra le due tecnologie più discusse.
I modelli NLP basati su GPT
OpenAI, ha introdotto il suo primo modello transformer con GPT nel 2018 e già allora le prestazioni erano strabilianti sia nella traduzione sia nella produzione di testo. Nel 2019 è stato rilasciato GPT-2 e nel 2020 GPT-3, ogni volta incrementando il numero di parametri e con prestazioni incredibilmente migliorate. GPT-3 ha raggiunto un segmento di popolazione e un’attenzione sui social incredibilmente elevati rispetto sia ai GPT precedenti sia ad altri modelli concorrenti. Contestualmente sono iniziate le approvazioni e le critiche del pubblico e delle istituzioni, sono nati progetti paralleli concorrenti da parte di community di sviluppatori e data scientist. L’anno 2023 ha visto il rilascio di GPT-4 noto come ChatGPT, lo stato dell’arte di OpenAI e dei suoi modelli transformer.
Non è importante probabilmente quale sia il modello migliore, ma bisogna osservare che la popolazione mondiale sta discutendo dei Large Language Model che attualmente hanno le loro migliori prestazioni sulla base dei Transformer; una tecnologia attorno alla quale si svilupperanno i prossimi anni di ricerca nell’ambito dell’intelligenza artificiale, applicata sia al NLP sia agli altri ambiti.


