
Andrew NG, un riferimento a livello mondiale nell’ambito dell’intelligenza artificiale, ha affermato recentemente che la Computer vision sarà una rivoluzione pari a quella dei Large Language Model (LLM), i sistemi che abbiamo recentemente imparato a conoscere grazie a ChatGPT. Modelli come CLIP, Kosmos, ma anche GPT4 (anche se la funzionalità non è ancora utilizzabile dal pubblico) riescono già ad elaborare testo e immagini in un unico contesto, ma Google DeepMind fa uno step ulteriore con RT-2, aggiungendo a tutto questo le azioni di un robot.
Si parla, infatti di “embodied intelligence” e di modelli VLA (Vision-Language-Action), e oggi approfondiamo proprio questa tematica.

Indice degli argomenti:
Il percorso verso la multimodalità: i VLM (Vision-Language models)
“Il futuro delle interazioni uomo-macchina sarà multimodale? Sì, perché vogliamo dare all’AI i nostri sensi per comprendere il mondo”. Con questa frase, a dicembre 2022 concludevo il mio intervento al Search Marketing Connect.
È abbastanza semplice intuire che, se vogliamo costruire macchine dalle capacità comparabili a quella degli esseri umani, abbiamo bisogno di qualcosa che va oltre ai modelli di linguaggio. Perché noi umani siamo multimodali: non costruiamo la nostra comprensione del mondo basandoci solo sul testo. Abbiamo gli occhi, le orecchie, abbiamo il tatto… tutti i nostri sensi ci aiutano a costruire una rappresentazione di ciò che ci circonda.
Di conseguenza, è naturale che la ricerca si diriga verso la progettazione di modelli che non elaborano solo testo, ma anche altri input (modelli multimodali). Una delle strade più entusiasmanti dell’innovazione legata all’intelligenza artificiale e che riguarda questo ambito, riguarda senza dubbio i VLM (Vision-Language model).
Da VLM (Vision-Language model) a VLA (Vision-Language-Action)
I modelli legati alla Computer vision come CLIP di OpenAI o Kosmos di Microsoft, non solo gestiscono il testo, ma possono elaborare anche immagini.
L’immagine che segue mostra alcune interazioni di un modello dello stesso tipo sviluppato dalla Carnegie Mellon University. Il suo nome è Gill, è meno noto di quelli nominati in precedenza, ma ci aiuta a capire meglio la natura di un’interazione multimodale e del suggerimento visivo.
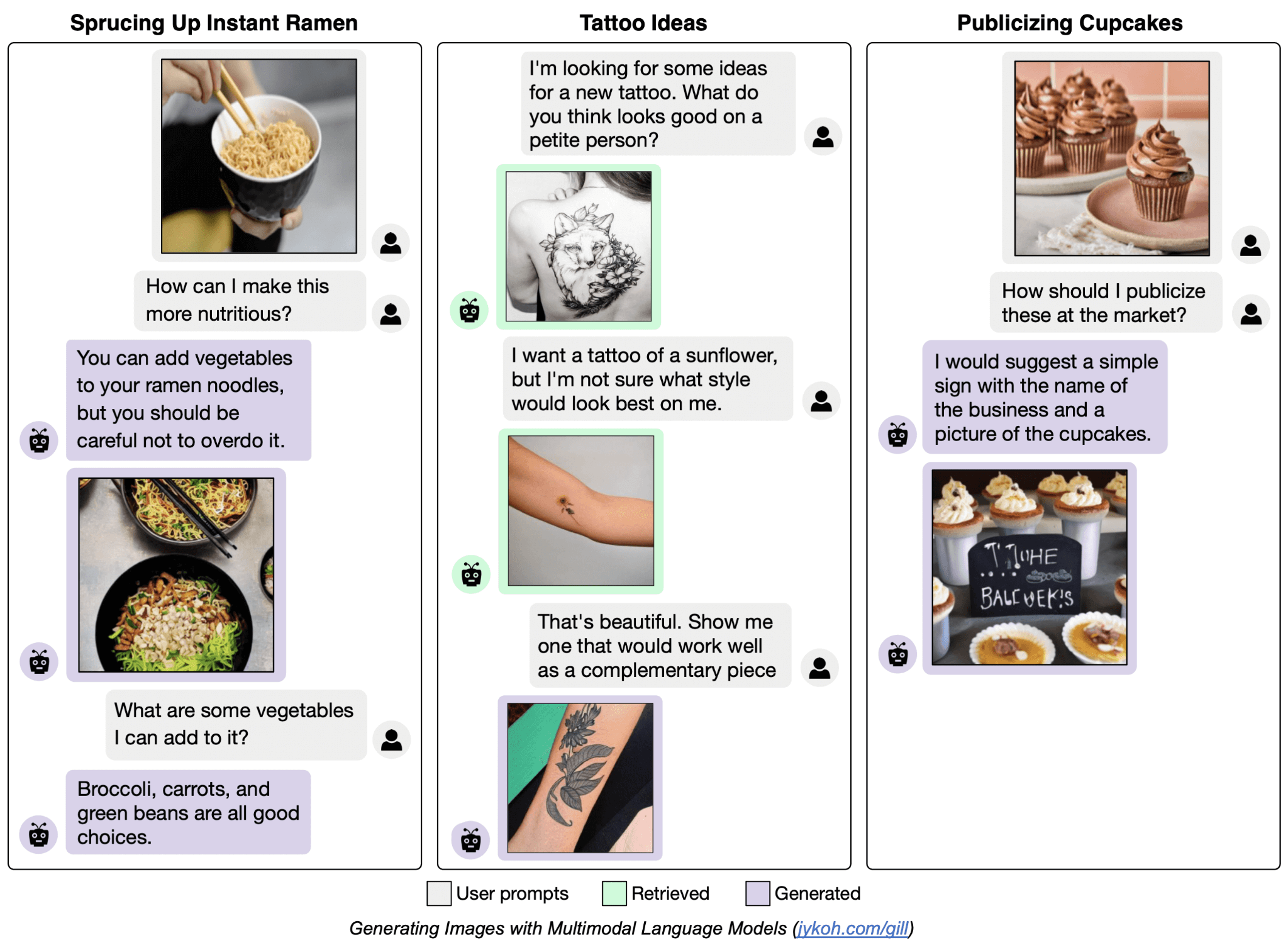
Google DeepMind sta facendo un ulteriore passo avanti, portando questi modelli nel mondo fisico, ovvero nel campo della robotica. Infatti, perfezionando i VLM sia con compiti di linguaggio visivo (es. rispondere a domande sulle immagini), sia con dati legati alla robotica, è possibile ottenere dai modelli delle azioni oltre al semplice testo.
Questa evoluzione può essere definita Vision-Language-Action (VLA). In breve, i VLA sono modelli in grado di generare azioni che un robot può mettere in atto per eseguire il movimento desiderato.
Possiamo dire, in modo estremamente semplicistico, che si tratta di un “ChatGPT con la capacità di interpretare le immagini e controllare i robot”.
Usare un VLM ottimizzato su dati robotici di alta qualità
Con l’idea di portare la robotica al livello successivo, Google ha fatto una scommessa: i ricercatori hanno ipotizzato che si possano usare VLM, modelli che hanno accesso a dati di testo e immagini praticamente su scala web, e utilizzare le rappresentazioni apprese da quei modelli per trasferirle ai robot.
E visto che dare a un robot con una conoscenza semantica di alto livello del mondo basata su “dati robotici” è probabilmente utopia (perché i dati non sarebbero abbastanza), cosa succederebbe se si usasse un modello VLM esistente ottimizzato su dati robotici di alta qualità?
Ed è proprio questa l’idea e la struttura del cambiamento che è alla base dei VLA.
VLA, il principio di funzionamento
I VLA lavorano esattamente come LLM e VLM, ossia grazie a token. Prevedono le informazioni che, in base al training che hanno ricevuto, hanno la maggior probabilità di essere corrette in un contesto.
Spesso, infatti, per spiegare in maniera molto semplice il funzionamento dei modelli di linguaggio, viene associato all’autocompletamento che ci assiste quando scriviamo dei messaggi con lo smartphone.
Ma invece di prevedere token di testo, come fa ChatGPT, ad esempio, i modelli VLA come RT-2 sono anche in grado di prevedere le azioni che un robot deve eseguire in base alle informazioni che ha a disposizione. Quindi in base alle osservazioni delle telecamere ad esso collegate, come possiamo vedere nell’immagine che segue.
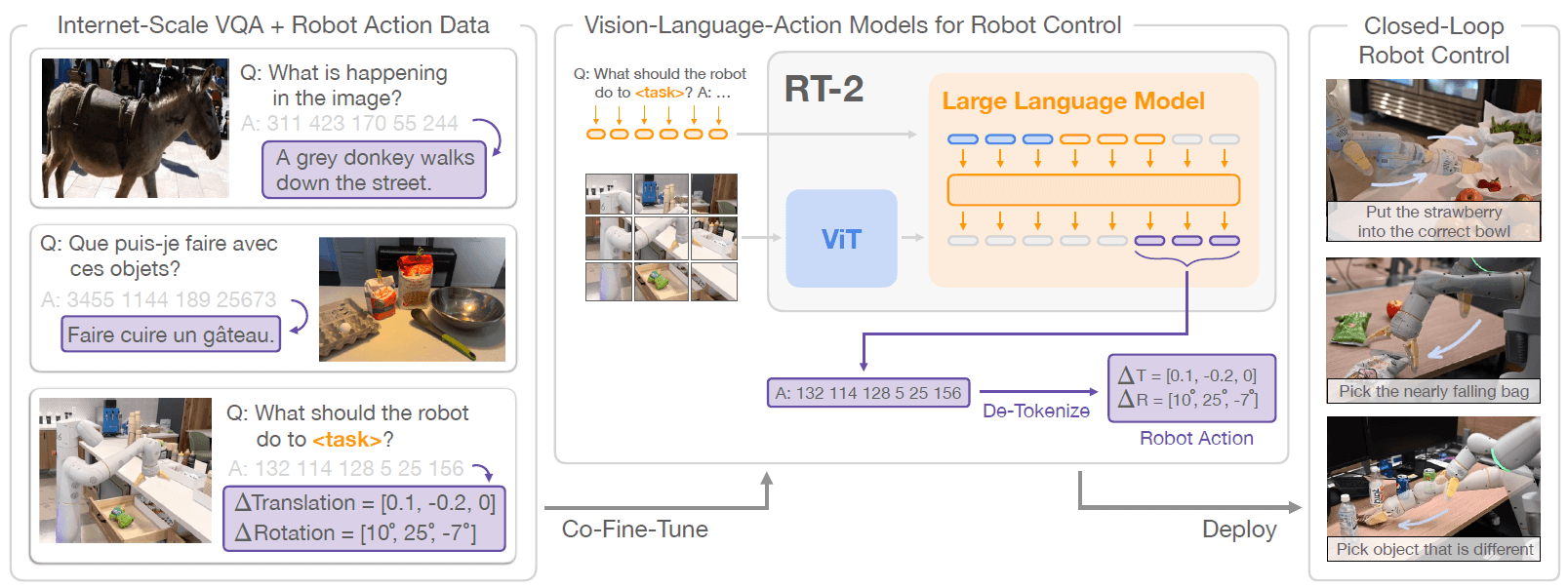
Fonte: paper Google DeepMind “RT-2:Vision-Language-ActionModels TransferWebKnowledgetoRoboticControl”
I risultati ottenuti nella valutazione di RT-2, rispetto ad altri sistemi di “AI robotics”, sono stati decisamente convincenti, come possiamo vedere dal diagramma che segue.
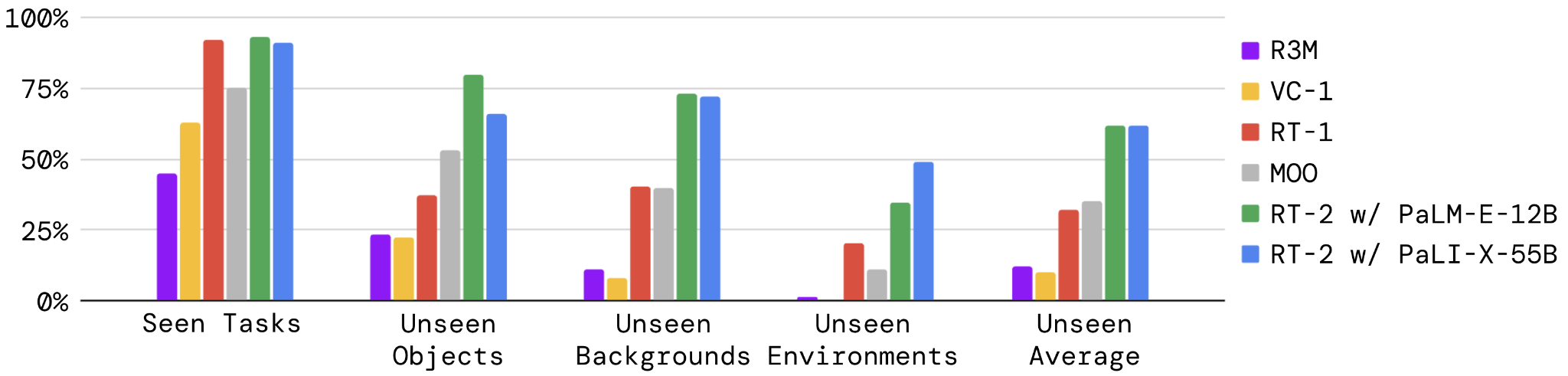
Fonte: paper Google DeepMind “RT-2:Vision-Language-ActionModels TransferWebKnowledgetoRoboticControl”
L’aspetto più interessante è rappresentato dal fatto che RT-2 ha dimostrato ottime performance in situazioni non apprese durante l’addestramento, che riguardano oggetti o ambienti (generalizzazione), sviluppando anche nuove capacità inaspettate derivanti dalla scala di conoscenza linguistica dei VLM (emergenza).
Tra le oltre seimila prove che Google ha fatto svolgere al robot, alcune includono le seguenti azioni impressionanti.

Fonte: Google DeepMind
In uno dei task che si vedono nell’immagine, ad esempio, il robot è riuscito a “capire” la posizione errata del sacchetto di patatine, permettendogli di rispondere perfettamente alla richiesta.
Per eseguire questa azione, il modello, grazie alla conoscenza semantica delle immagini catturate dalla fotocamera, ha constatato che il sacchetto sull’orlo del tavolo potrebbe cadere, mentre l’altro (al centro del tavolo) no.
Nell’esempio in basso a destra, invece, il modello non solo comprende la differenza tra un polpo e un asino, ma è anche in grado di interpretare il termine “animale terrestre“, associandolo a quest’ultimo.
Con un approccio più quantitativo, Google ha valutato il modello in base a tre benchmark: comprensione dei simboli, ragionamento, riconoscimento umano.
Sorprendentemente, RT-2 ha ottenuto ottime performance in tutti, dimostrandosi capace di eseguire azioni come quelle che si vedono nell’immagine che segue.
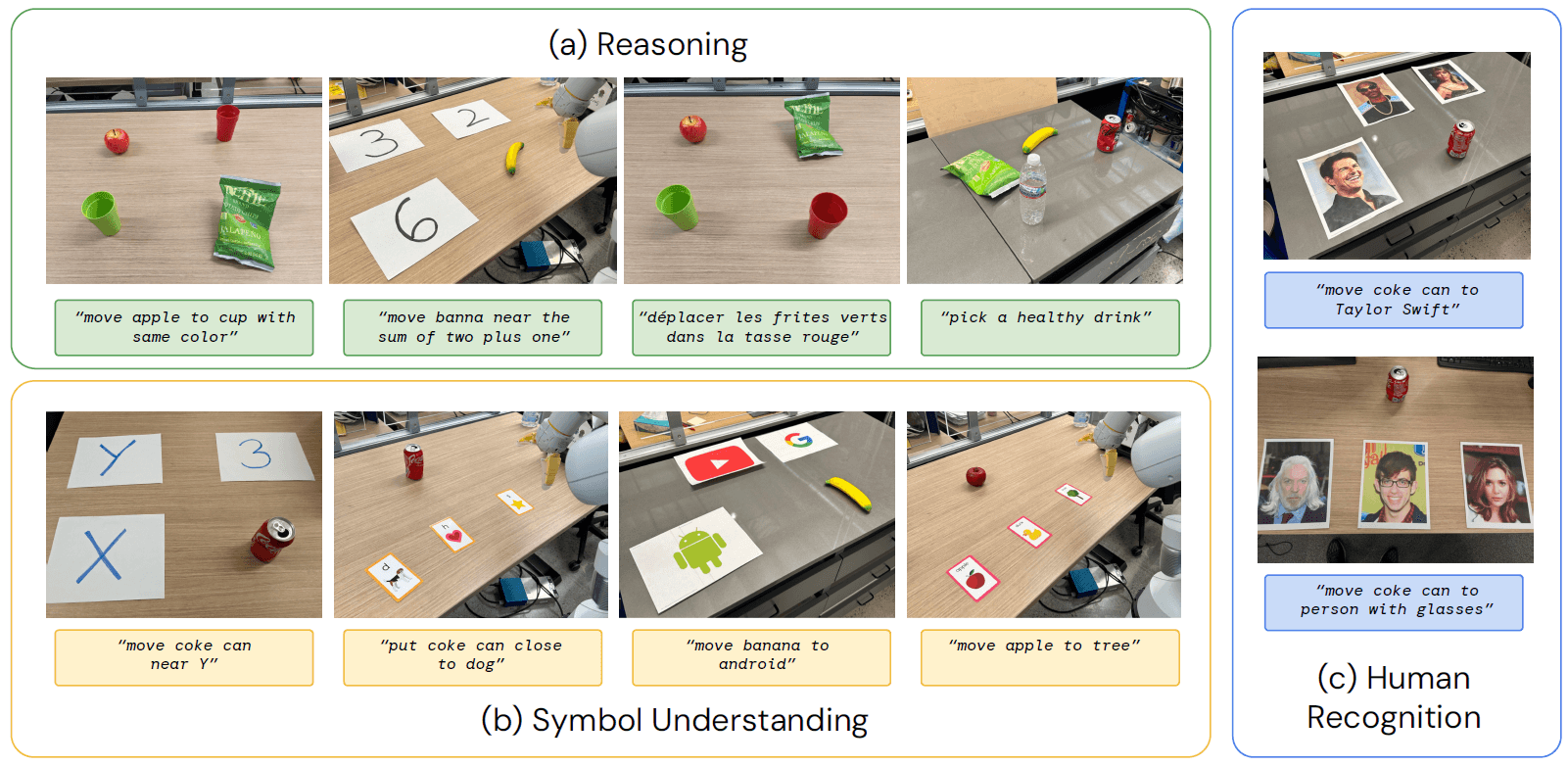
Fonte: paper Google DeepMind “RT-2:Vision-Language-ActionModels TransferWebKnowledgetoRoboticControl”
Appare chiare come RT-2 riesca a performare anche in situazioni complesse, che implicano capacità di comprensione, per le quali non era stato addestrato.
In conclusione, possiamo dire che, anche se l’aggiunta di un modello di linguaggio visivo non ha permesso la creazione di nuovi movimenti robotici (come specificato nel paper di Google DeepMind) ha trasferito una conoscenza semantica consistente al robot, rendendolo più consapevole su concetti complessi come il posizionamento, il riconoscimento degli oggetti e il ragionamento logico.
Conclusioni
Conoscendo i principi di funzionamento di modelli di questo tipo, non ci si dovrebbe stupire. Tuttavia, quando vediamo il risultato finale risulta davvero difficile non farlo.
I limiti sono ancora tanti, e, di certo, sarà necessario riflettere anche dal punto di vista della sicurezza, ma è abbastanza chiaro come questi sviluppi, in poco tempo, potrebbero migliorare di molto i processi produttivi delle aziende.
Possiamo dire che RT-2 è il primo passo verso nuove frontiere della robotica e dell’intelligenza artificiale. Quale sarà il prossimo?





