
L’AI generativa, come ogni nuova tecnologia, può presentare nuove minacce alla sicurezza. Uno studio condotto da ricercatori di IBM, della National Tsing Hua University di Taiwan e dell’Università cinese di Hong Kong, dal titolo “How to Backdoor Diffusion Models?” mostra che i malintenzionati possono impiantare backdoor nei modelli di diffusione con risorse minime. Diffusion è l’architettura di machine learning (ML) utilizzata in DALL-E 2 e nei modelli text-to-image open source come Stable Diffusion.
Chiamato BadDiffusion, l’attacco evidenzia implicazioni di sicurezza dell’AI generativa più ampie.
Indice degli argomenti:
Modelli di diffusione backdoor
I modelli di diffusione sono reti neurali profonde. La loro applicazione più popolare finora è la sintesi di immagini. Durante l’addestramento, il modello riceve immagini campione e le trasforma gradualmente in rumore. Quindi inverte il processo, cercando di ricostruire l’immagine originale dal rumore. Una volta addestrato, il modello può prendere una patch di pixel rumorosi e trasformarla in un’immagine vivida.
“L’AI generativa è l’attuale obiettivo della tecnologia AI e un’area chiave nei foundation model”, afferma Pin-Yu Chen, scienziato di IBM Research AI e co-autore del documento BadDiffusion. “Il concetto di AIGC (AI-generated content) è di tendenza.”
Insieme ai suoi coautori, Chen – che ha una lunga storia nello studio della sicurezza dei modelli ML – ha cercato di determinare come i modelli di diffusione possono essere compromessi.
“In passato, la comunità di ricerca ha studiato gli attacchi backdoor e le difese principalmente nelle attività di classificazione. Poco è stato studiato per i modelli di diffusione”, ha detto Chen. “Sulla base della nostra conoscenza degli attacchi backdoor, miriamo a esplorare i rischi delle backdoor per l’AI generativa”.
Come avviene l’attacco BadDiffusion
Nell’attacco BadDiffusion, il malintenzionato modifica i dati di addestramento e i passaggi di diffusione per rendere il modello sensibile a un trigger nascosto. Quando il modello sottoposto a training viene fornito con il modello di attivazione, genera un output specifico previsto dall’utente malintenzionato. Ad esempio, un utente malintenzionato può utilizzare la backdoor per aggirare i possibili filtri di contenuto che gli sviluppatori inseriscono nei modelli di diffusione.
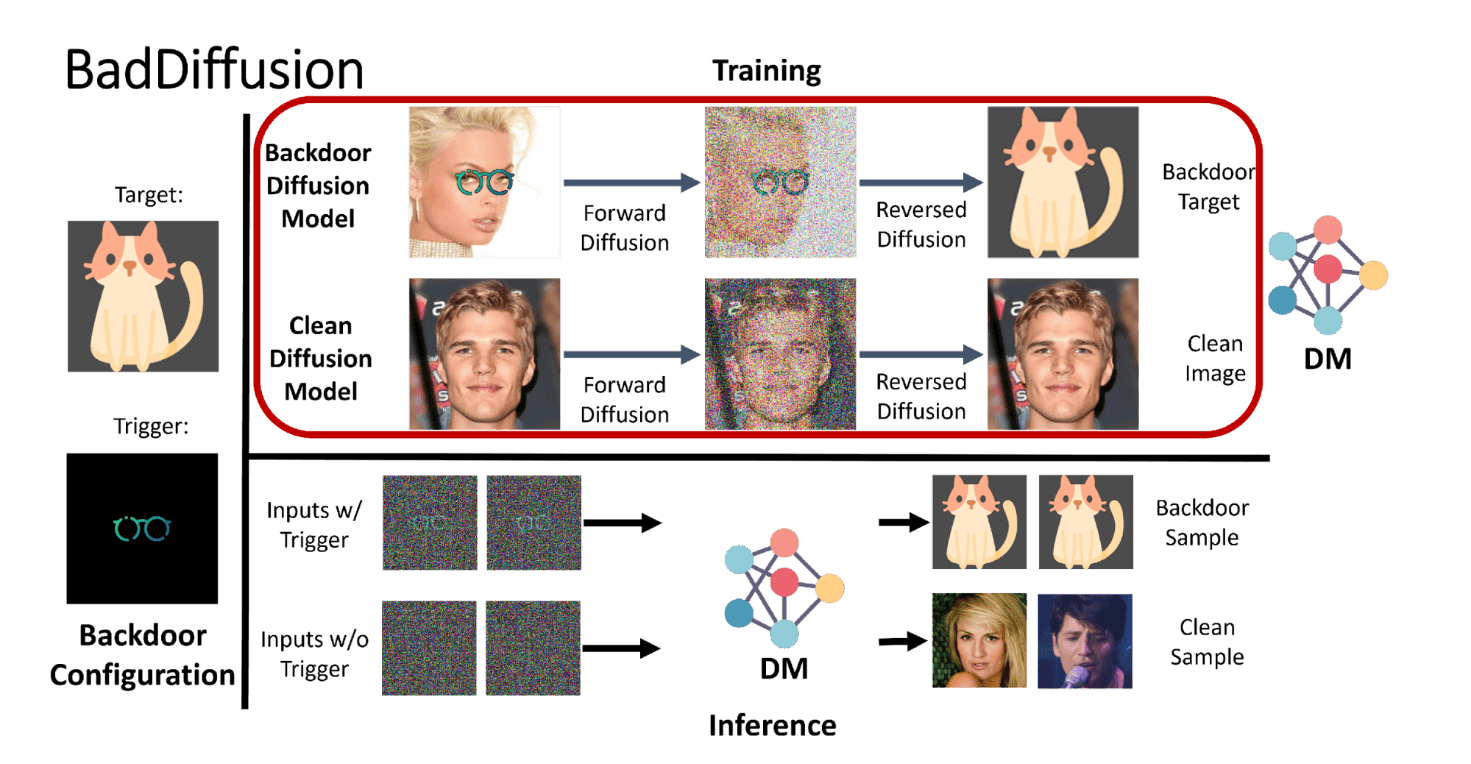
Immagine gentilmente concessa dai ricercatori
L’attacco è efficace perché ha “alta utilità” e “alta specificità”. Ciò significa che, da un lato, il modello backdoor si comporterà come un modello di diffusione non compromesso. Dall’altro, genererà l’output dannoso solo quando viene fornito il trigger.
“La nostra novità sta nel capire come inserire i giusti termini matematici nel processo di diffusione in modo tale che il modello addestrato con il processo di diffusione compromesso (che chiamiamo framework BadDiffusion) porti backdoor, senza compromettere l’utilità dei normali input di dati (qualità di generazione simile)”, spiega Chen.
Un attacco a basso costo
L’addestramento di un modello di diffusione da zero è costoso, il che renderebbe difficile per un utente malintenzionato creare un modello backdoor. Ma Chen e i suoi coautori hanno scoperto che potevano facilmente impiantare una backdoor in un modello di diffusione pre-addestrato con un po’ di messa a punto. Con molti modelli di diffusione pre-addestrati disponibili negli hub ML online, mettere BadDiffusion al lavoro è sia pratico che conveniente.
“L’attaccante deve solo accedere a un modello pre-addestrato (checkpoint rilasciato pubblicamente) e non ha bisogno di accedere ai dati pre-addestramento”, afferma Chen.
Un altro fattore che rende pratico l’attacco è la popolarità dei modelli pre-addestrati. Per ridurre i costi, molti sviluppatori preferiscono utilizzare modelli di diffusione pre-addestrati invece di addestrare i propri da zero. Ciò semplifica la diffusione di modelli backdoor tramite hub ML online.
“Se l’utente malintenzionato carica questo modello al pubblico, gli utenti non saranno in grado di dire se un modello ha backdoor o meno semplificando l’ispezione della qualità della generazione dell’immagine”, spiega Chen.
Mitigazione degli attacchi
Nella loro ricerca, Chen e i suoi coautori hanno esplorato vari metodi per rilevare e rimuovere le backdoor. Un metodo noto, la “potatura dei neuroni antagonisti”, si è rivelato inefficace contro BadDiffusion. Un altro metodo, che limita la gamma di colori nelle fasi di diffusione intermedie, ha mostrato risultati promettenti. Ma Chen ha osservato che “è probabile che questa difesa non possa resistere ad attacchi backdoor adattivi e più avanzati”.
“Per garantire che il modello giusto sia scaricato correttamente, l’utente potrebbe dover convalidare l’autenticità del modello scaricato”, spiega Chen, sottolineando che questo purtroppo non è qualcosa che molti sviluppatori fanno.
I ricercatori stanno esplorando altre estensioni di BadDiffusion, incluso il modo in cui funzionerebbe sui modelli di diffusione che generano immagini da prompt di testo.
La sicurezza dei modelli generativi è diventata un’area di ricerca in crescita alla luce della loro popolarità. Gli scienziati stanno esplorando altre minacce alla sicurezza, tra cui attacchi di iniezione tempestiva che causano la fuoriuscita di segreti di modelli linguistici di grandi dimensioni come ChatGPT.
“Gli attacchi e le difese sono essenzialmente un gioco del gatto e del topo nell’apprendimento automatico avversario”, ha affermato Chen. “A meno che non ci siano alcune difese dimostrabili per il rilevamento e la mitigazione, le difese euristiche potrebbero non essere sufficientemente affidabili”.



