
Il New York Times ha bloccato il web crawler di OpenAI, il che significa che OpenAI non può utilizzare i contenuti della pubblicazione per addestrare i suoi modelli di intelligenza artificiale. Se si controlla la pagina robots.txt del NYT, si può vedere che il NYT non consente GPTBot, il crawler che OpenAI ha introdotto all’inizio di agosto. In base alla Wayback Machine di Internet Archive, sembra che il NYT abbia bloccato il crawler già il 17 agosto.
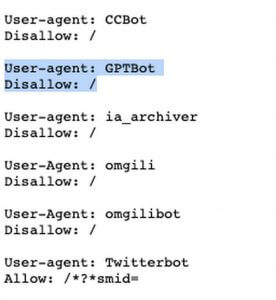
Uno snippet del robots.txt del NYT che mostra che l’azienda ha disabilitato GPTBot
Il passo arriva dopo che il NYT ha aggiornato i suoi termini di servizio all’inizio di agosto per proibire l’uso dei suoi contenuti per addestrare modelli di intelligenza artificiale. Il portavoce del New York Times, Charlie Stadtlander, non ha voluto commentare. OpenAI non ha risposto immediatamente a una richiesta di commento.
Il NYT sta anche valutando la possibilità di intraprendere un’azione legale contro OpenAI per violazione dei diritti di proprietà intellettuale. Se dovesse intentare una causa, il Times si unirebbe ad altri, come Sarah Silverman e altri due autori, che a luglio hanno citato in giudizio l’azienda per l’uso di Books3, un set di dati utilizzato per addestrare ChatGPT che potrebbe contenere migliaia di opere protette da copyright, e Matthew Butterick, un programmatore e avvocato che sostiene che le pratiche di scraping dei dati dell’azienda equivalgono alla pirateria software.
Indice degli argomenti:
Il New York Times contro OpenAI
Gli avvocati del quotidiano Usa stanno valutando se fare causa a OpenAI per proteggere i diritti di proprietà intellettuale associati ai suoi servizi, secondo quanto riferito da due persone direttamente a conoscenza delle discussioni.
Per settimane, il Times e il produttore di ChatGPT sono stati in trattative tese per raggiungere un accordo di licenza in base al quale OpenAI avrebbe pagato il Times per incorporare le sue storie negli strumenti di intelligenza artificiale dell’azienda tecnologica, ma le discussioni sono diventate così controverse che il giornale sta ora prendendo in considerazione l’azione legale.
Un’azione legale da parte del Times contro OpenAI darebbe vita a quella che potrebbe essere la più importante battaglia legale sulla protezione del copyright nell’era dell’intelligenza artificiale generativa.
Una delle principali preoccupazioni del Times è che ChatGPT stia diventando, in un certo senso, un concorrente diretto del giornale, creando testi che rispondono a domande basate sui resoconti e gli scritti originali dello staff del giornale.
È un timore accentuato dalle aziende tecnologiche che utilizzano strumenti di AI generativa nei motori di ricerca. Microsoft, che ha investito miliardi in OpenAI, sta ora alimentando il suo motore di ricerca Bing con ChatGPT.
Se una persona che effettua una ricerca online riceve una risposta lunga un paragrafo da uno strumento di intelligenza artificiale che rielabora le notizie del Times, la necessità di visitare il sito web dell’editore diminuisce notevolmente, ha dichiarato una persona coinvolta nelle trattative.
I cosiddetti modelli linguistici di grandi dimensioni, come ChatGPT, hanno analizzato vaste parti di Internet per assemblare i dati che informano il modo in cui il chatbot risponde alle varie richieste. Il data-mining è condotto senza autorizzazione. Se l’acquisizione di questo enorme archivio sia legale rimane una questione aperta.

Se OpenAI ha violato la legge federale, gli articoli violati vanno distrutti
Se si scoprisse che OpenAI ha violato i diritti d’autore, secondo la legge federale gli articoli violati andrebbero distrutti alla fine del processo.
In altre parole, se un giudice federale scopre che OpenAI ha copiato illegalmente gli articoli del New York Times per addestrare il suo modello di AI, il tribunale potrebbe ordinare all’azienda di distruggere il set di dati di ChatGPT, costringendola a ricrearlo utilizzando solo il lavoro che è autorizzata a usare.
La legge federale sul diritto d’autore prevede anche severe sanzioni finanziarie: i trasgressori rischiano multe fino a 150mila dollari per ogni violazione “commessa intenzionalmente”.
“Se si copiano milioni di opere, si può capire come questo numero diventi potenzialmente fatale per un’azienda”, ha dichiarato Daniel Gervais, co-direttore del programma di proprietà intellettuale della Vanderbilt University che studia l’AI generativa. “La legge sul copyright è una spada che pende sulla testa delle aziende di AI per diversi anni, a meno che non trovino il modo di negoziare una soluzione”.
A giugno, l’amministratore delegato del Times, Meredith Kopit Levien, ha dichiarato al Cannes Lions Festival che è giunto il momento che le aziende tecnologiche paghino la loro parte per l’utilizzo dei vasti archivi del giornale.
“Ci deve essere uno scambio di valore equo per i contenuti che sono già stati utilizzati e per quelli che continueranno a essere usati per addestrare i modelli”, ha detto.
Lo stesso mese, Alex Hardiman, chief product officer del giornale, e Sam Dolnick, deputy managing editor, hanno descritto in una nota al personale una nuova iniziativa interna volta a cogliere i potenziali vantaggi dell’intelligenza artificiale.
Tra i loro timori principali hanno citato la “protezione dei nostri diritti”: “Come possiamo garantire che le aziende che utilizzano l’AI generativa rispettino la nostra proprietà intellettuale, i nostri marchi, le nostre relazioni con i lettori e i nostri investimenti?”.
Ogni potenziale causa intentata dal New York Times si aggiungerebbe ad altre azioni legali simili intentate contro OpenAI nelle ultime settimane. Anche altre aziende di AI generativa, come Stability AI, che distribuisce il generatore di immagini Stable Diffusion, sono state colpite da cause per copyright.
Getty Images ha citato in giudizio Stability AI per aver presumibilmente addestrato un modello di intelligenza artificiale su oltre 12 milioni di foto di sua proprietà senza averne l’autorizzazione.



