
I ricercatori di Microsoft hanno pubblicato un nuovo modello di generazione del codice, phi-1, progettato per essere “leggero”. Phi-1 è in grado di superare GPT-3.5, il modello linguistico di grandi dimensioni alla base di ChatGPT.
Il modello basato su Transformer vanta solo 1,3 miliardi di parametri – in confronto, Codex, il modello OpenAI che ha costituito la base di quello che sarebbe diventato GitHub Copilot, aveva 12 miliardi di parametri.
I ricercatori di Microsoft hanno impiegato solo quattro giorni per addestrare phi-1 utilizzando otto chip A100 di Nvidia. Il modello è stato addestrato su sei miliardi di token provenienti dal web e su un altro miliardo di token generati con GPT-3.5, uno dei modelli di base utilizzati per costruire ChatGPT di OpenAI.
Per quanto riguarda le prestazioni, phi-1 ha ottenuto un’accuratezza pass@1 del 50,6% nella prova di HumanEval e il benchmark HumanEval. Il modello Microsoft ha battuto StarCoder di Hugging Face e ServiceNow (33,6%), GPT-3.5 di OpenAI (47%) e PaLM 2-S di Google (37,6%), nonostante le dimensioni sostanzialmente inferiori.
Nel test MBPP pass@1, phi-1 è andato meglio, ottenendo un punteggio del 55,5%. Molti dei modelli sopra citati non hanno ancora pubblicato risultati su questo benchmark, ma WizardLM’s WizardCoder ha ottenuto il 51,5% in un test condotto all’inizio del mese. WizardCoder è un modello da 15 miliardi di parametri, contro gli 1,3 miliardi di phi-1.
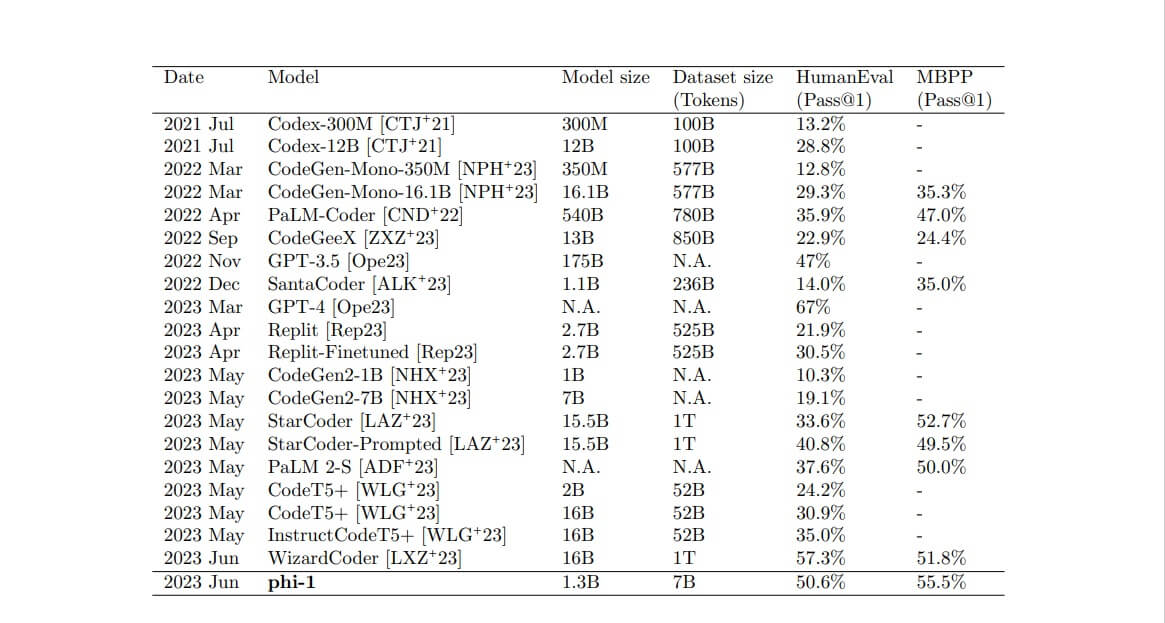
Nonostante sia addestrato su scala molto più piccola, phi-1 supera i modelli concorrenti su HumanEval e MBPP, ad eccezione di GPT-4 (anche WizardCoder ottiene HumanEval migliore ma MBPP peggiore).
Indice degli argomenti:
I dati di alta qualità fanno la differenza
I ricercatori di Microsoft sostengono che è la “potenza dei dati di alta qualità” a far sì che phi-1 ottenga risultati così buoni. Per sottolineare il punto, i ricercatori hanno intitolato il documento del loro modello “I libri di testo sono tutto ciò che serve“.
“Proprio come un libro di testo completo e ben fatto può fornire a uno studente le conoscenze necessarie per padroneggiare una nuova materia, il nostro lavoro dimostra il notevole impatto dei dati di alta qualità nell’affinare la competenza di un modello linguistico nei compiti di generazione del codice”, scrivono.
“Creando dati di ‘qualità da manuale’ siamo riusciti ad addestrare un modello che supera quasi tutti i modelli open-source su benchmark di codifica come HumanEval e MBPP, pur essendo 10 volte più piccolo in termini di dimensioni del modello e 100 volte più piccolo in termini di dimensioni del dataset”.
Phi-1 è limitato alla codifica Python, rispetto ad altri modelli di codifica disponibili. Il modello è limitato anche perché non possiede le conoscenze specifiche del dominio di modelli più grandi, come la programmazione con API specifiche.
Per ampliare il loro lavoro, i ricercatori di Microsoft hanno suggerito di utilizzare GPT-4 anziché GPT-3.5 per generare dati sintetici per l’addestramento del modello.
I ricercatori cercheranno anche di migliorare la diversità e la non ripetitività del set di dati, anche se il team ha dichiarato di dover trovare il modo di “iniettare casualità e creatività nel processo di generazione dei dati, pur mantenendo la qualità e la coerenza degli esempi”.
ZeRO++ per accelerare la messa a punto di grandi modelli
Questa settimana i ricercatori di Microsoft hanno anche annunciato ZeRO++ un nuovo metodo progettato per migliorare il pre-training e la messa a punto dei modelli di grandi dimensioni.
I modelli di intelligenza artificiale di grandi dimensioni, come ChatGPT e GPT-4, richiedono grandi risorse di memoria e di calcolo per l’addestramento e la messa a punto.
A volte, quando l’addestramento avviene su un numero elevato di GPU rispetto alla dimensione del batch, si ottiene una piccola dimensione del batch per GPU, che richiede una comunicazione frequente.
Per risolvere questo problema, Microsoft ha introdotto ZeRO++, un sistema che sfrutta la quantizzazione – il processo di mappatura di valori infiniti continui in un insieme più piccolo di valori finiti discreti – combinata con i dati e la rimappatura delle comunicazioni, per ridurre il volume totale delle comunicazioni di 4 volte rispetto a ZeRO, senza incidere sulla qualità del modello.
In effetti, ZeRO++ è progettato per migliorare la comunicazione tra il modello che si sta cercando di addestrare e le GPU se l’hardware utilizzato è troppo piccolo rispetto alle dimensioni del modello.
Secondo i ricercatori di Microsoft, ZeRO++ consente ai cluster a bassa larghezza di banda di raggiungere un throughput simile a quello di cluster con larghezza di banda 4 volte superiore.
Il team che sta dietro al sistema sostiene che offre un throughput fino a 2,2 volte superiore rispetto a ZeRO, il precedente sistema di ottimizzazione della formazione di Microsoft.
ZeRO++ è disponibile per chiunque nella comunità dell’intelligenza artificiale ed è accessibile tramite GitHub. I ricercatori hanno annunciato che una versione per la chat sarà rilasciata “nelle prossime settimane”.



